

AI modellerini production'a deploy etmek, bir notebook'ta çalıştırmaktan temelden farklıdır. GPU bellek yönetimi, container orkestrasyon, asenkron işleme ve auto-scaling — çoğu rehberin tamamen atladığı zorluklar.
Bu makale, gerçek bir production sistemine dayanan uçtan uca kapsamlı bir rehberdir. AKS cluster oluşturmadan, işlenmiş sonucun kullanıcının eline ulaştığı ana kadar her şeyi — yedi katman derinliğinde — anlatır.
1. GPU İş Yükleri için AKS Kurulumu

AI iş yükleri için AKS cluster oluştururken en kritik karar node pool stratejisidir. GPU iş yükleri ayrı bir user pool'da çalışmalıdır — GPU'ları system pool'da çalıştırmak para israfıdır ve kaynak çakışması yaratır.
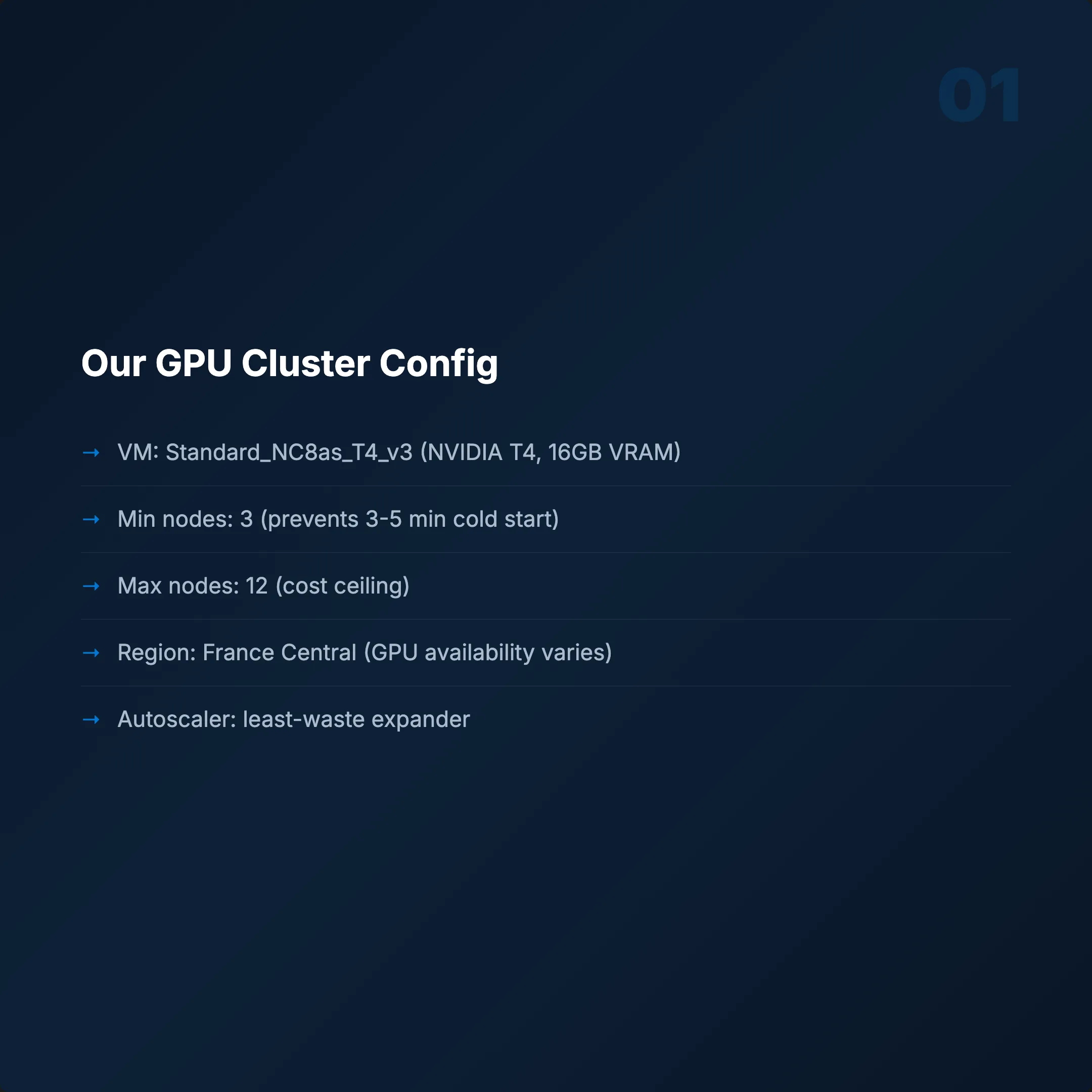
Cluster Konfigürasyonu
- VM: Standard_NC8as_T4_v3 (NVIDIA T4, 16 GB VRAM)
- Min node: 3 (cold start'ı önler — GPU açılışı 3–5 dakika sürer)
- Max node: 12 (maliyet tavanı)
- Region: France Central (GPU erişilebilirliği bölgeye göre değişir)
- Autoscaler: Cluster autoscaler +
least-wasteexpander
least-waste expander, en az kaynak israf eden node tipini seçer. Birden fazla VM seçeneğiniz olduğunda en verimli olanı tercih eder.
Sık Yapılan Hatalar
- GPU node'ları her bölgede mevcut değil. Taahhüt vermeden önce
az vm list-skusçalıştırın. - GPU için Spot instance? Riskli. İşlem ortasında preempt edilen node = kaybolan iş.
- Min 3 node opsiyonel değil. Kullanıcılar soğuk bir GPU'nun ayağa kalkması için 3–5 dakika beklemez.
2. AI Modelini Production API'ye Dönüştürmek

FastAPI + Uvicorn kullanıyoruz — async destek, otomatik OpenAPI dokümantasyonu ve Flask'tan hızlı. Ama asıl sorun framework değil, GPU eşzamanlılık modelidir.
Dört Kritik Karar
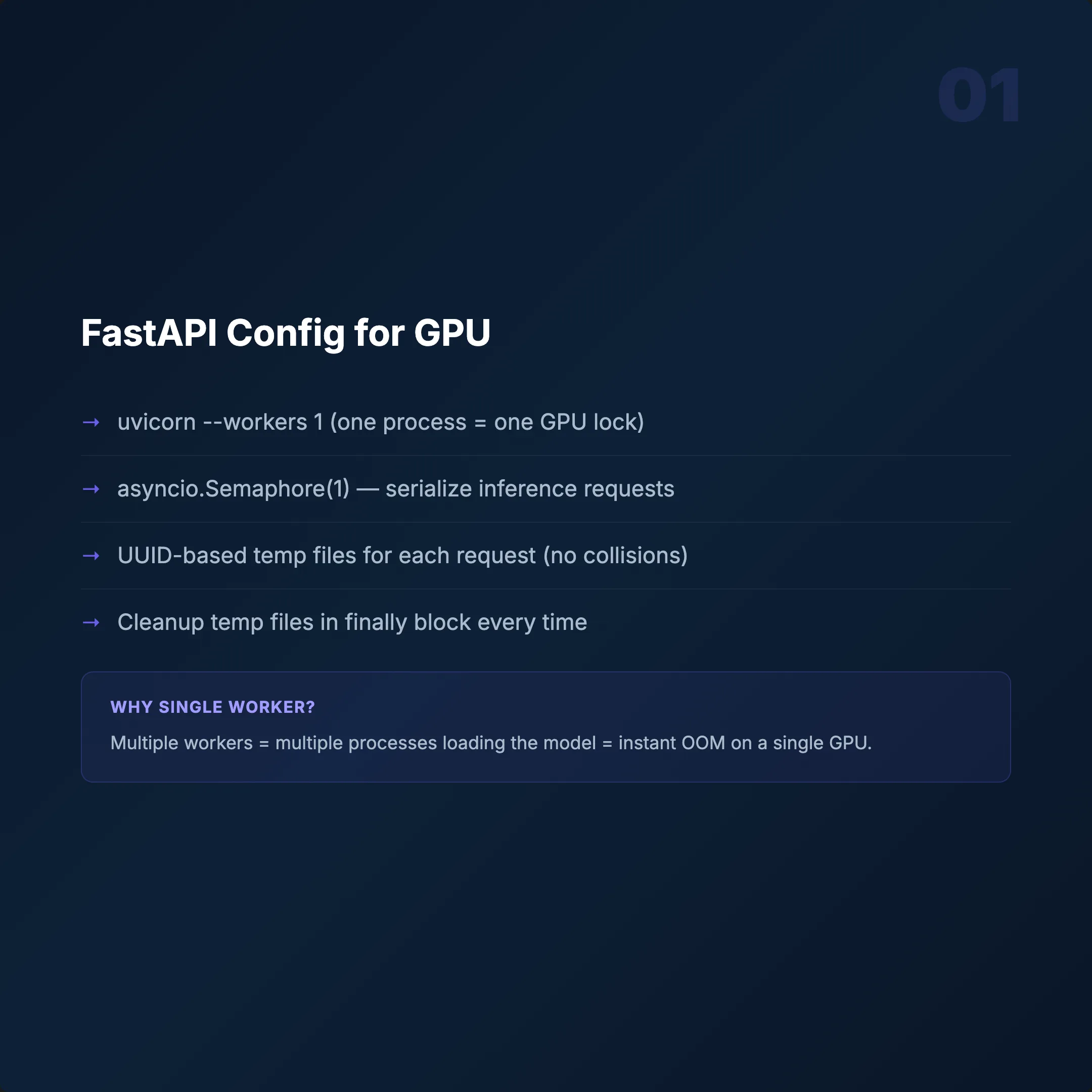
Tek Worker: uvicorn --workers 1
GPU belleği thread-safe değil. Eşzamanlı inference = bellek çakışması = crash. Daha fazla container ile ölçeklendirin, daha fazla thread ile değil.
Semaphore(1)
Container başına aynı anda yalnızca bir inference. İkinci istek bekler. Basit, öngörülebilir, kararlı.
Başlangıçta Model Yükleme
Modelleri container başlangıcında bir kez yükleyin, her istekte değil. ONNX Runtime GPU, ham PyTorch'a göre %30–40 daha hızlı inference sağlar.
Geçici Dosya Yönetimi
Her istek için UUID tabanlı dosya adları ve işlem sonrası temizlik. Bunu atlarsanız /tmp dolar — container sessizce ölür.
Sağlık Endpoint'leri — Ayrı Tutun
/work→ Liveness (container hayatta mı?)/health→ Readiness (meşgul mü, boş mu?)
Bunları birleştirirseniz Kubernetes ölüyü meşgulden ayırt edemez. İşlem ortasındaki sağlıklı container'ları yeniden başlatır.
3. GPU Docker Container Oluşturma

GPU container'ı normal bir Docker imajı değildir. CUDA, cuDNN, PyTorch, ONNX Runtime — hepsi birbirine bağımlı. Versiyon uyumsuzluğu 1 numaralı hata kaynağıdır.
Base Image ve Bağımlılıklar
- Base:
nvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04 - Python: 3.10
- PyTorch: 2.0.1+cu118
- ONNX Runtime GPU: Ayrı kurulum (pip varsayılanı CPU-only!)
CUDA Versiyon Uyumsuzluğu — Neden Çalışır
CUDA 12.1 runtime üzerinde CUDA 11.8 PyTorch mu? Evet. PyTorch kendi CUDA kütüphanelerini paketler. Host runtime sürücü seviyesindeki işlemleri yönetir. Birlikte çalışırlar. Bu birçok kişiyi yanıltır.
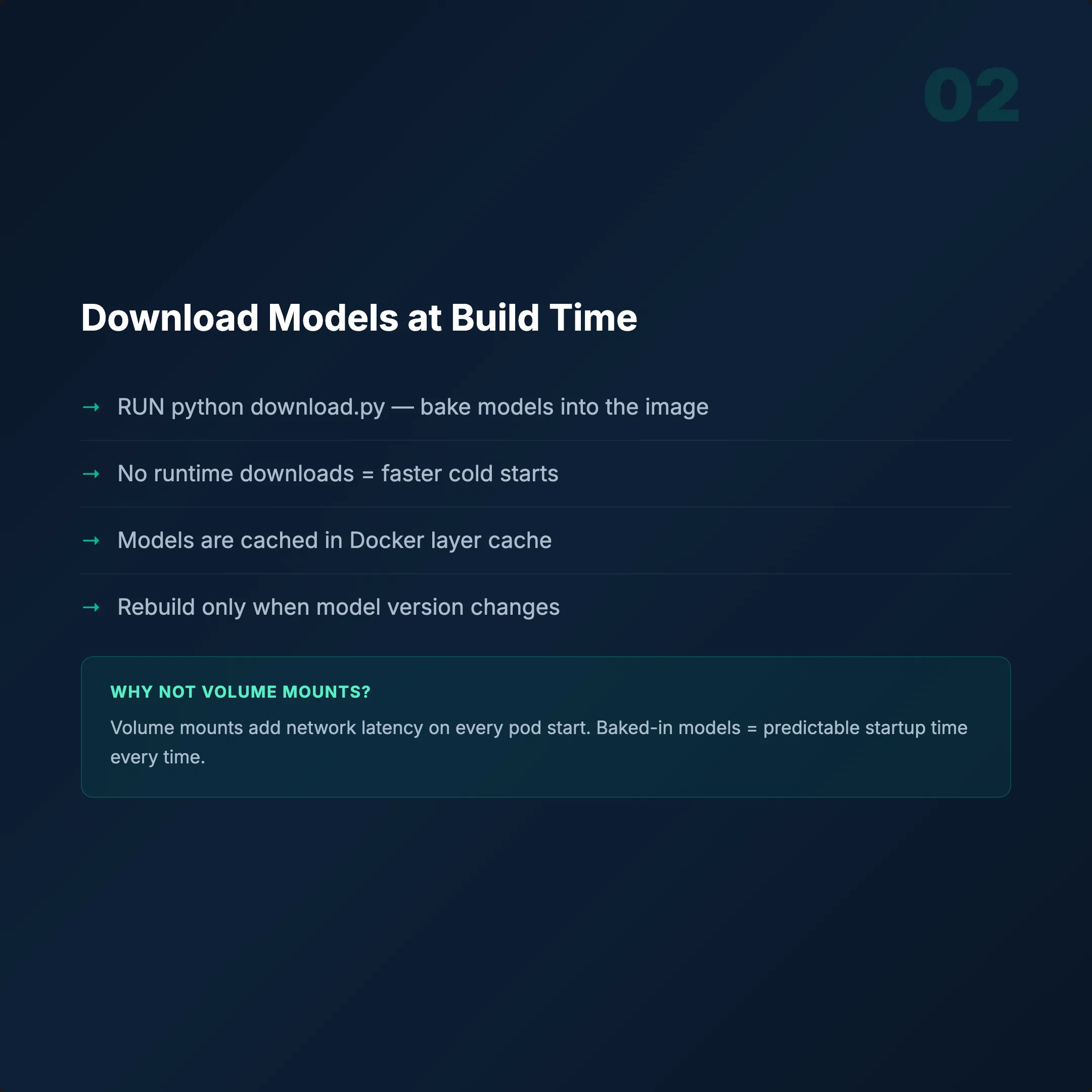
En Önemli Kural: Modelleri Build Zamanında İndirin
Dockerfile'ınıza RUN python download.py ekleyin. Model ağırlıklarını imaja gömün.
- Olmadan: Her pod hizmet vermeden önce 2–5 dk indirme yapar.
- İle: Cold start 10 saniyenin altına düşer.
İmaj boyutu 12–18 GB olacak. GPU container'ları için normal. Multi-stage build'ler build araçlarını kaldırmaya yardımcı olur, ama GPU kütüphaneleri büyüktür. Bununla savaşmayın.
docker build --platform linux/amd64 -t registry/app:latest .4. GPU'ya Özel Kubernetes Deployment

Readiness probe'unuz 10. saniyede ateşlenir. Modeliniz 55. saniyede yüklenmesini bitirir. Trafik gelir. Pod çöker. GPU deployment'ların çoğunun başarısız olduğu yer burasıdır.
Kaynak İstekleri
nvidia.com/gpu: 1— pod başına bir GPU garantisi- Bellek: 4Gi request, 8Gi limit
- nodeSelector: GPU node pool'unuzu hedefleyin
Probe'lar (Çoğu Kişinin Başarısız Olduğu Yer)
- Readiness:
GET /work,initialDelay: 60s - Liveness:
GET /work,initialDelay: 120s,period: 30s
Neden 60s readiness? Model GPU belleğine yüklenmeye zaman ister. Erken probe = hazır olmayan pod'a trafik yönlendirilir = anında 500 hatası. Neden 120s liveness? Aynı sebep + tampon. Kubernetes'in hâlâ başlatılmakta olan sağlıklı bir pod'u öldürmesine izin vermeyin.
Diğer Kritik Ayarlar
- Rolling update:
maxSurge %25,maxUnavailable %25 terminationGracePeriod: 30s(devam eden isteklerin bitmesini bekleyin)- tmpfs volume: Hızlı geçici dosya I/O için
emptyDir - Service:
LoadBalancer, port 80 → 8000
docker push registry/app:latest
kubectl rollout restart deployment/app
kubectl rollout status deployment/app5. Senkron HTTP Neden Başarısız — Service Bus Mimarisi

Kullanıcı istek gönderir. 30 saniye bekler. Zaman aşımı. Tekrar dener. Artık 3 özdeş iş GPU kaynaklarını yakıyor.
GPU inference'ı 10–30 saniye sürer. Senkron HTTP yanlış kalıptır.
Sorun
- Client HTTP isteği gönderir
- GPU 15–25 saniye işler
- Client timeout (genellikle 30s)
- Client otomatik tekrar dener
- 2–3 özdeş iş aynı anda çalışır
- GPU israfı + mükerrer sonuçlar
Çözüm: Azure Service Bus + Async Kuyruk
- Client istek gönderir → anında
202 Accepted+ task ID - İş Service Bus kuyruğuna gider
- Function App alır → GPU'ya gönderir
- Client task ID ile tamamlanana kadar yoklar
Neden Service Bus?
- Garantili teslimat — mesajlar kaybolmaz
- KEDA entegrasyonu — 1 mesaj = 1 pod talebi
- Dead-letter kuyruğu — başarısız işler otomatik ayrıştırılır
- Peek lock — işlem süresince mesaj kilitlenir
Kuyruk aynı zamanda doğal backpressure sağlar. GPU'lar aşırı yüklendiğinde, işler pod'ları çökertmek yerine kuyrukta bekler.

6. 3 Katmanlı Auto-Scaling: Sıfır GPU İsrafı

Tek bir HPA, GPU iş yükleri için yeterli değil. Azure Function App tarafından orkestre edilen 3 katmanlı bir sistem inşa ettik — sadece bir kuyruk tüketicisi değil, tüm operasyonun beyni.
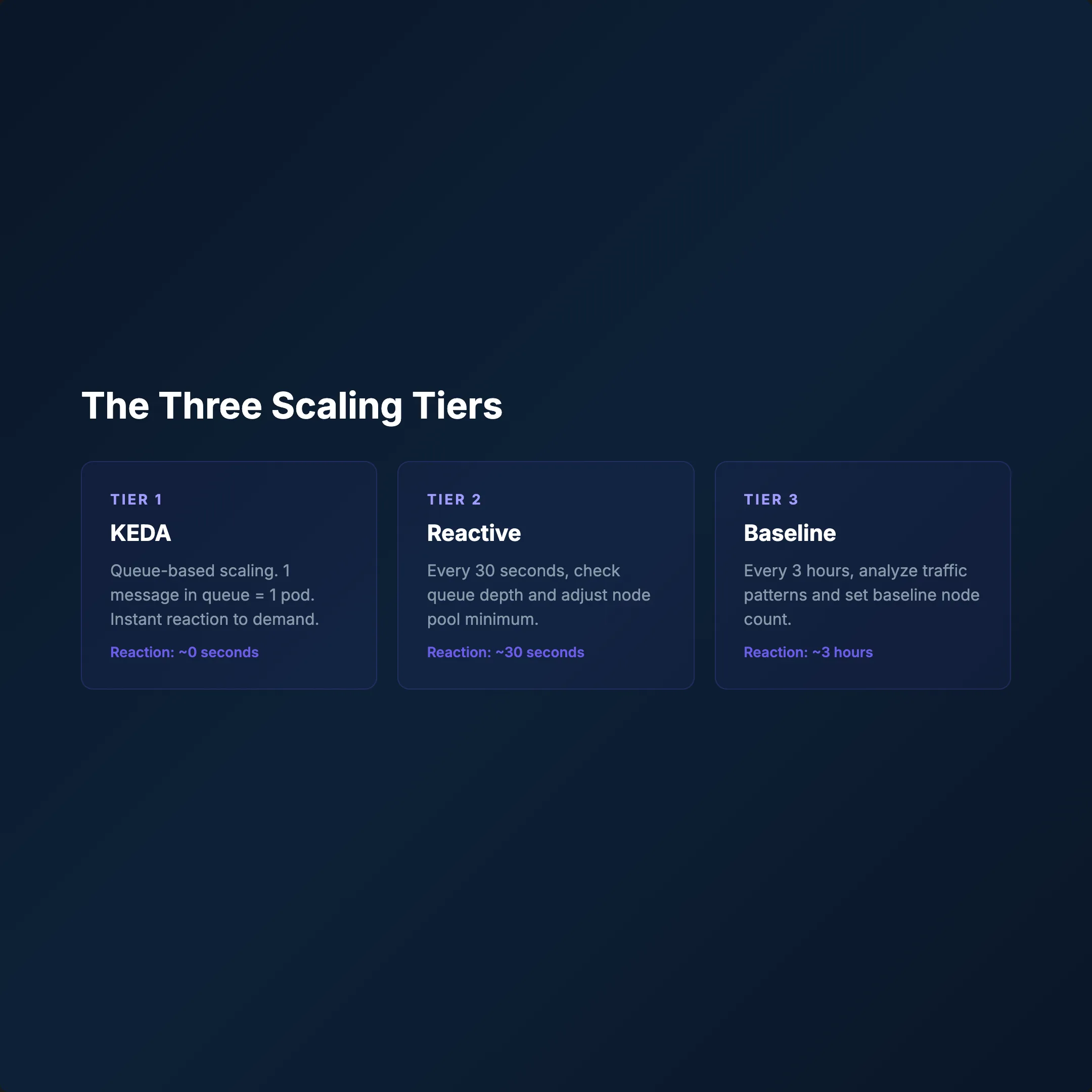
Katman 1 — KEDA (Event-Driven)
Kuyruk derinliği pod'ları tetikler. 1 mesaj = 1 pod talebi. Tepki süresi: saniyeler.
Katman 2 — Reaktif Monitör (Her 30s)
- Veritabanından aktif iş sayısını okur
- İşler > pod'lar → KEDA
minReplica'yı anında günceller - Yeni node'lar dakikalar içinde ayağa kalkar
- Günlük zirve metriğini günceller
Katman 3 — Baseline Ayarlayıcı (Her 3s)
- Son 3 saatteki zirve yükü analiz eder
- Yeni baseline hesaplar (min 3, max 12 node)
kubectl patchile KEDAminReplicaCount'u günceller
Neden 3 Katman?
- KEDA kuyruk derinliğine saniyeler içinde tepki verir
- Reaktif Monitör kuyruğun kaçırdığı ani yüklenmeleri yakalar
- Baseline Ayarlayıcı gereksiz scale-down'ları önler
Mekanizma: Function App → Azure Management REST API → kubectl patch. SemaphoreSlim(1,1) yarış koşullarını önler.
Sonuç: Zirve → scale up. Düşük trafik → 3 node. Sıfır GPU israfı.
7. Uçtan Uca: Tam İstek Akışı

Sisteme bir istek geldiğinde tam olarak ne olur:
- CLIENT → API'ye görsel + parametreler gönderir
- .NET API GATEWAY → kimlik doğrulama, kredi kontrolü
- API → MongoDB'de task oluşturur + Service Bus'a kuyruğa alır → anında
202+ task ID döner - FUNCTION APP → mesajı alır → GPU kapasitesini kontrol eder
- GPU POD → işi işler:
- Girdi dosyalarını indirir
- Algılama çalıştırır
- Inference çalıştırır (ONNX GPU)
- Çıktı kalitesini artırır
- Stream döner
- FUNCTION APP → sonucu alır → CDN yükleme → DB durumu: tamamlandı
- CLIENT →
GET /result/{taskId}yoklar → CDN URL alır
Toplam süre: 15–30 saniye.
Arka Planda Sürekli Çalışan İşler
- KEDA kuyruk derinliğini izler
- Reaktif Monitör her 30s kontrol eder
- Baseline Ayarlayıcı her 3 saatte yeniden hesaplar
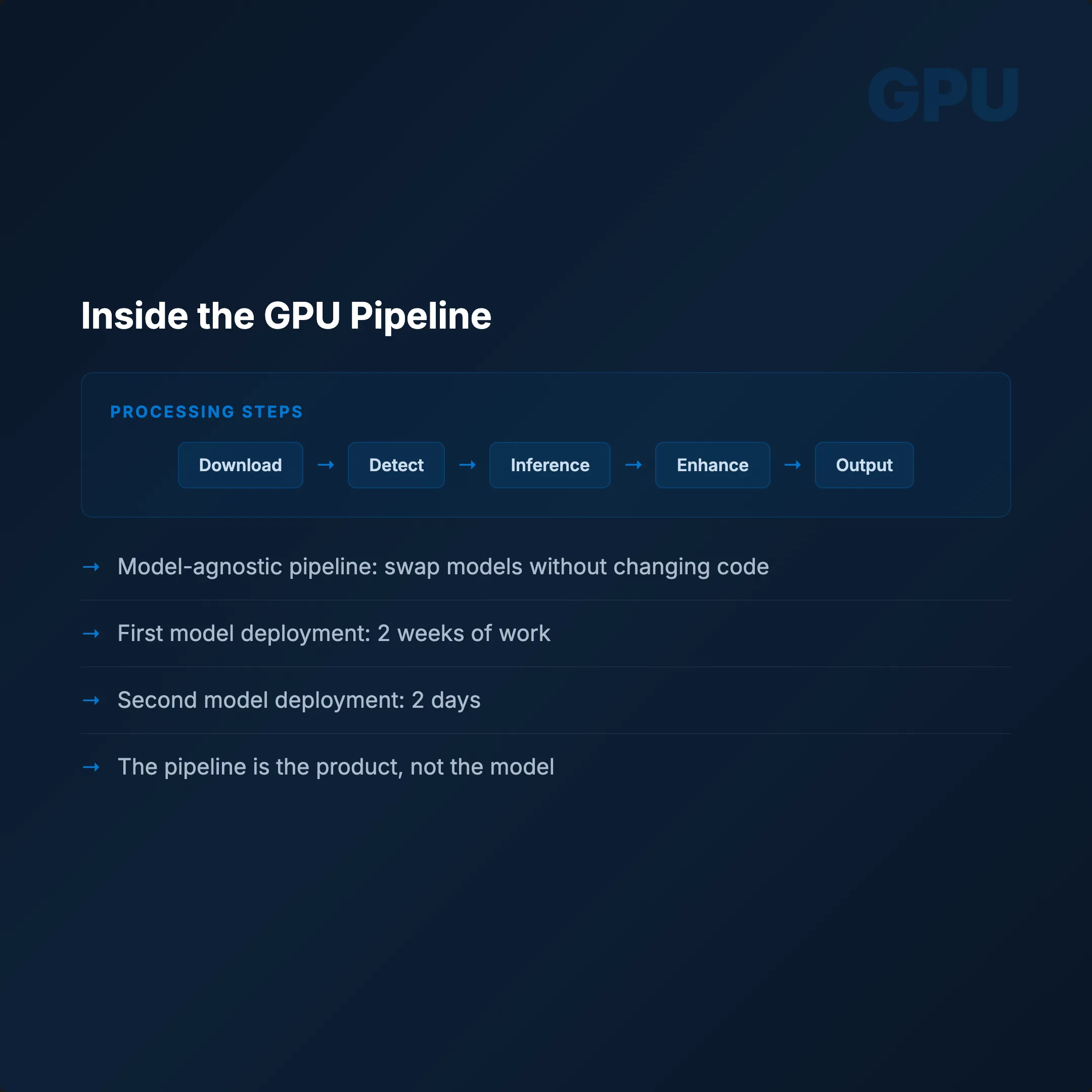
Tüm pipeline model-agnostiktir. Ağırlıkları değiştirin, endpoint'i ayarlayın, geri kalan her şey aynı kalır. İlk model: deploy etmek 2 hafta. İkinci model: 2 gün. Aynı Dockerfile. Aynı manifest'ler. Farklı ağırlıklar.
Sonuç
Kubernetes üzerinde production AI servisi kurmak, sadece bir modeli çalıştırmakla ilgili değildir. Hataları zarif bir şekilde ele alan, hassas şekilde ölçeklenen ve boşta kalan GPU'larda para yakmayan bir sistem inşa etmekle ilgilidir.
Temel mimari kararlar:
- Uygun autoscaler konfigürasyonu ile ayrı GPU node pool'ları
- Tek worker'lı, semaphore korumalı API container'ları
- Build zamanında Docker imajına gömülmüş modeller
- GPU başlatma süresine saygı duyan cömert probe gecikmeleri
- Timeout çığını ortadan kaldıran async kuyruk mimarisi
- Saniyelerde tepki veren ve saatler üzerinden optimize eden 3 katmanlı ölçeklendirme
Pipeline'ı bir kez kurun. Sonsuza dek yeniden kullanın.
